Canvas
Stable Diffusion XL
LMD
Ours
(Hover mouse to see our results)








Prompt Inspiration










Diffusion models have been shown as the state-of-the-art methods to generate realistic and diverse images based on text prompts, powering models like Stable Diffusion, MidJourney and DALL·E. However, stable diffusion still often make mistakes regarding generating accurately according to numerical information and the object positions. This work proposes a new method to solve the object position problem by letting users draw bounding boxes of objects to indicate their location, which to be used as part of the input, besides providing text prompts only. Our model then utilizes Layout-Grounded Stable Diffusion from Lian et al. as the backbone to solve the numeracy question so that the actual number of objects in the generated image could match the number specified in the original text prompt. By composing objects onto the positions specified by the user, our model can accurately generate images with numerical and positional information coherent with the text prompt. Through our work, we identify the best coefficients for the above steps using Fréchet Inception Distance. In addition, our model also introduces more diverse and specific user input through integrating a canvas interface that supports specifying image generation subject location and size.
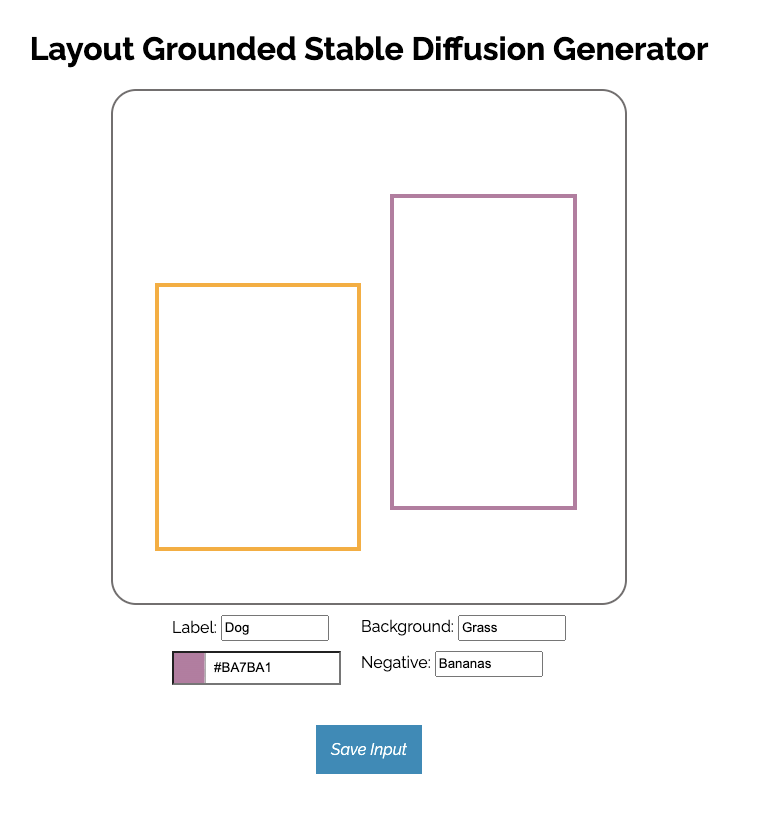
For our product, we utilize a canvas interface to introduce a creative artistic canvas for the user
to freely define a framework for their desired image. Through this canvas, you can draw bounding boxes
at desired locations and label the object whatever you want (e.g. a cat on the left).
Moreover, you can define the desired background of this photo (e.g. on grass).
Lastly, you can also define the negative prompt - whatever you wish to not appear in the image.
After pressing the Save Input button, this canvas will generate a .json file.
This file can later be used to pass into the model.
Unfortunately, given our time and technical constraints, we weren't able to host the canvas interface along with the model on one server. This is a future development!
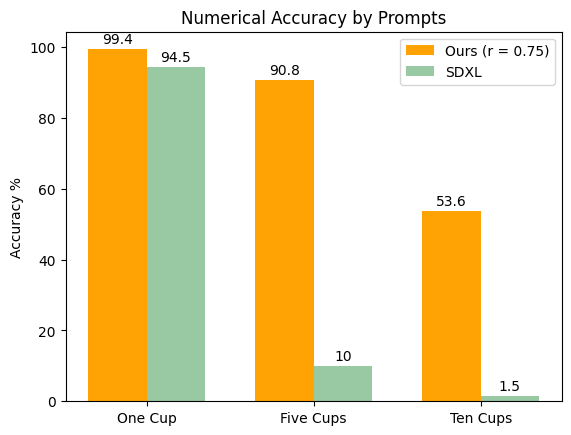
We generated 500 images with prompts "A realistic image of one cup", "A realistic image of five cups", and "A realistic image of ten cups". The model can generate accurate images when the task is relatively simple. However, as the task is more demanding, the model is more likely to create more objects than needed or have two objects merged together.
We generated 1000 images with fixed bounding boxes and varied frozen step ratio \(r\) for two prompts: "A realistic image of a dog" and "A realistic image of a flower".
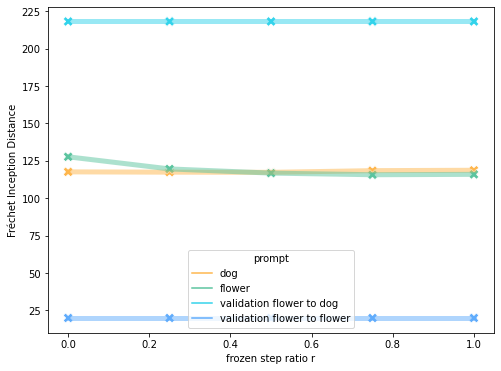
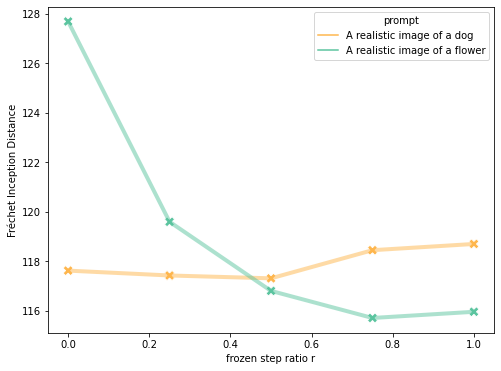
We noticed two major causes to decrease numerical accuracy in generated images:

Objects interact, causing a single masked latent to encapsulate multiple objects.

Diffusion model may use the prompt to produce similar objects in the background.
Layout-grounded Generative Model, by Lian et al., is a novel controller is introduced to guide an existing diffusion model, such as Stable Diffusion, which originally lacks this specific training objective. This guidance ensures adherence to the layout generated in the initial phase. The process of generating the image in this stage involves two main steps: generating masked latents for each object specified in the layout (e.g., cats and dogs) with attention control to ensure accurate placement within the designated boxes, followed by the coherent composition of these masked latents onto the background noisy image. This results in a final image that aligns with the specified foreground and background based on the text prompt.
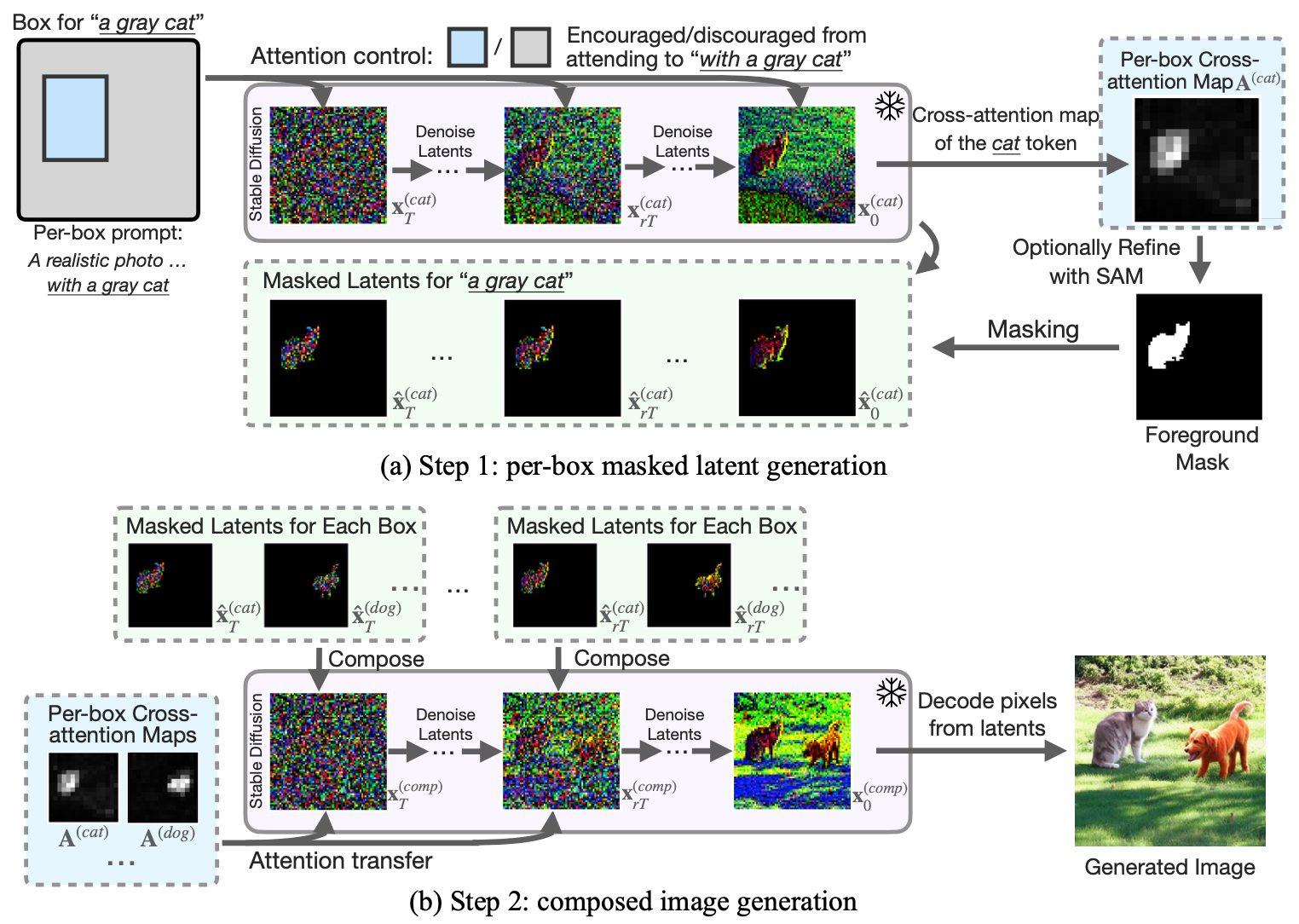
In the layout-grounded model, a critical parameter is Frozen Step Ratio, \(r\), which represents the ratio of the number of time steps during which the masked latents and the background image are composed, to the total number of steps in the reverse diffusion process.





We would like to thank Professor Cloninger and Professor Saab for all the instructions in the past two quarters. Thanks to our beloved Suraj for leading this wonderful capstone project, our TA Keng-Chi for his help. Last but not least, thanks for the hard working DSMLP GPUs.